
Chúng tôi rất vui mừng chia sẻ kiến thức về từ khóa Outlier la gi để tối ưu hóa nội dung trang web và chiến dịch tiếp thị trực tuyến. Bài viết cung cấp phương pháp tìm kiếm, phân tích và lựa chọn từ khóa phù hợp, cùng với chiến lược và công cụ hữu ích. Hy vọng thông tin này sẽ giúp bạn xây dựng chiến lược thành công và thu hút lưu lượng người dùng. Cảm ơn sự quan tâm và hãy tiếp tục theo dõi blog để cập nhật kiến thức mới nhất.
Outliers/anomalies (tài liệu ngoại lai/tài liệu thất thường) là một trong những thuật ngữ được sử dụng rất rộng rãi trong thế giới data và nhất là data science. Xác định và loại bỏ outliers là một bước cực kỳ quan trọng trong quá trình xử lý tài liệu. Việc xử lý các tài liệu ngoại lai sẽ giúp tăng cao độ xác thực cho những mô hình dự đoán hay các báo cáo giải trình doanh nghiệp một cách đáng kể.
Bạn Đang Xem: Outliers – Hướng dẫn xác định và loại bỏ dữ liệu ngoại lai trên MySQL
Trong bài này tất cả chúng ta sẽ cùng tìm hiểu các vấn đề sau:
- Outliers thực chất là gì?
- Tầm quan trọng của việc xác định và loại bỏ outliers?
- Cùng so sánh và phân tích kết quả của trước và sau khoản thời gian loại bỏ outliers
- Phương pháp và các bước thực hiện loại bỏ Outliers
- Thực hiện xử lý Outliers bằng MySQL
- Cuối cùng là thắc mắc cho bạn thực hiện
Lưu ý: Nội dung bài viết sẽ không còn đi nghiên cứu quá sâu về Outliers. Bài này chỉ tạm dừng tại mức cơ bản để các chúng ta cũng có thể đọc, hiểu và thực hiện ngay.
Outliers (tài liệu ngoại lai) là gì?
Để hiểu được thực chất thực sự của outliers là gì, các bạn có trước tiên tham khảo các hình phía bên dưới. Lưu ý sự khác nhau giữa điểm red color với những điểm còn sót lại.

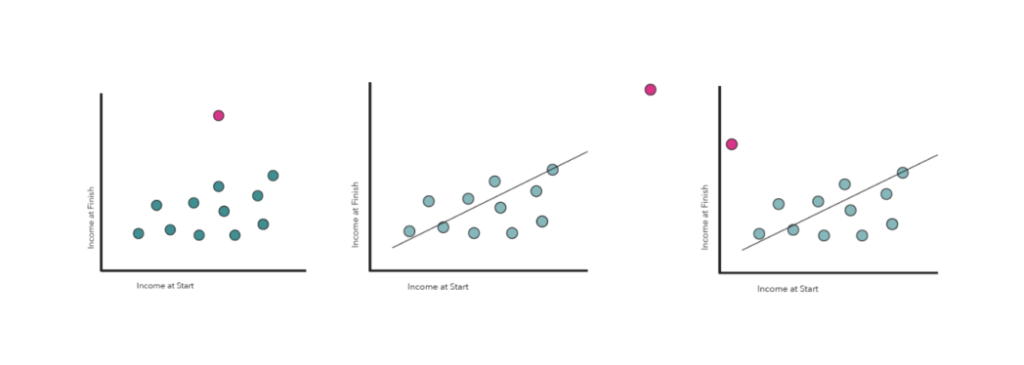
Qua các tấm hình trên, chắc các bạn cũng thấy được điểm chung của rất nhiều outliers. Hiểu đơn giản thì Outliers là một hoặc nhiều cá thể khác hẳn so với các thành viên còn sót lại của nhóm. Sự khác biệt này còn có thể dựa trên nhiều tiêu chí khác nhau như giá trị hay tính chất.
So với 2 hình trên, tất cả chúng ta có thể dễ dàng xác định các outliers dựa trên giá trị của chúng vì những giá trị này khác xa với những giá trị còn sót lại của nhóm.
Ví dụ: trong một lớp học gồm 100 học trò, phần lớn học trò đều đạt kết quả dao động từ 5 đến 7 riêng chỉ có một bạn đạt điểm 1 và một bạn đạt điểm 10. Trong trường hợp này, 2 bạn có điểm 1 và 10 có thể được xem là 2 Outliers cho bài kiểm tra đó.
Trong trường hợp khác thì những outliers là những thành phần có tính chất hoặc tính cách khác với số còn sót lại.

Ví dụ: một đơn vị với mô hình B2B có rất nhiều khách hàng khác nhau nhưng trong những khách hàng này còn có một doanh nghiệp tới từ nước ngoài. Doanh nghiệp nước ngoài này còn có thể được xem là một outliers khi xét về tính chất chất khách hàng. Vì họ có thể có những hành vi mua hàng rất khác với khách hàng trong nước.
Trên thực tế, người ta chia outliers ra khá nhiều loại khác nhau. Nhưng ở đây tôi chỉ muốn các bạn hiểu được thực chất của outliers và cách xác định những loại outliers đơn giản. Vậy nên mình gộp chung lại thành 2 dạng như trên.
Nếu muốn tìm hiểu xâu hơn về Outliers, các chúng ta cũng có thể Google về nó. Có nhiều tài liệu cả tiếng Anh lẫn tiếng Việt giảng giải về thuật ngữ này. Mình sẽ không còn phân tích sâu thêm nữa về khái niệm cũng như phân loại.
Khi nào cần xác định và loại bỏ outliers
Trên thực tế, khi tất cả chúng ta làm báo cáo giải trình hay xây dựng model, sẽ rất khó để đạt giá trị tuyệt đối. Trong hồ hết các trường hợp, tài liệu xấu hoặc thất thường sẽ luôn tồn tại. Những tài liệu này tồn tại do khá nhiều nguyên nhân khác nhau tùy vào hoàn cảnh và mô hình kinh doanh.
Một vài ví dụ cụ thể như:
- Lỗi phát sinh trong quá trình nhập và chỉnh sửa tài liệu như dư hay thiếu vài số 0 hay sai địa chỉ. Lỗi này mình thấy cực kỳ phổ thông.
- So với các mô hình trực tuyến, người ta có thể cố ý tạo ra giá trị ảo để test thị trường hoặc làm mồi nhử. Ví dụ một ngôi nhà có thể được ra bán với giá 100,000 đồng hay 999 tỷ. Nếu khách hàng tính trung bình giá nhà tại khu vực tính luôn cả nhà phía trên, đảm bảo giá nhà sẽ cao ngất ngưởng so với thực tế.
- Khi muốn biết tổng kinh phí sản phẩm đẩy ra trong thời gian ngày của một cửa hàng, tất cả chúng ta phát hiện có một vài ngày, số lượng này cao một cách đột biến so với những ngày còn sót lại. Nguyên nhân là vì gần đó có một sự kiện cộng đồng kiến khách hàng đột ngột tăng lên.
Tất cả chúng ta có thể thấy được với 2 ví dụ (1) và (2) thì những tài liệu xấu này cần được loại bỏ để tăng tính xác thực cho những model hoặc báo cáo giải trình. Tuy nhiên với trường hợp thứ (3), các outliers này lại sở hữu thể cho tất cả chúng ta thấy được một tiềm năng doanh thu mới. Nếu tất cả chúng ta tìm hiểu nguyên nhân vì sao lại sở hữu sale tăng đột biến và chuẩn bị sẵn sàng cho kỳ tiếp theo, khả năng là sẽ sở hữu thêm được nhiều lợi nhuận.
Vậy nên việc xác định Outliers là cấp thiết trong phần lớn các trường hợp. Nhưng việc xử lý chúng thế nào thì còn tùy thuộc vào từng hoàn cảnh. Tất cả chúng ta cần tìm hiểu sâu hơn nguyên nhân gây ra các Outliers trước lúc quyết định loại bỏ hay giữ lại những outliers này.
Phương pháp xác định Outliers
Vì thực chất của outliers có rất nhiều loại khác nhau nên cũng sẽ sở hữu nhiều phương pháp khác nhau để xác định outliers. Trong nội dung bài viết này tất cả chúng ta sẽ chỉ tập trung vào một trong những loại outliers là những data point có mức giá trị quá cao hoặc quá thấp so với phần lớn tài liệu.
Tất cả chúng ta sẽ sử dụng bộ tài liệu là SuperStore Sales và tìm outliers dựa trên tổng kinh phí của mỗi hóa đơn tại mỗi state. Với thắc mắc này, tài liệu mà tất cả chúng ta cần xử lý chỉ có một chiều (xem lại hình 2). Bạn nào chưa tồn tại tài liệu SupperStore thì xem hướng dẫn tại đây.

Xem Thêm : Viện Quản lý dự án ATOHA (Học Online, Offline, In-house)
Kết phù hợp với loại outliers, mình sẽ sử dụng phương pháp Extreme Value Analysis. Phương pháp này đơn giản là xác định các data points có mức giá trị cực cao/thấp (extreme value). Các giá trị extreme sẽ tiến hành xác định bằng khoảng tầm cách của chúng so với giá trị trung bình (Average/Mean). Toàn bộ các giá trị Extreme đều được xác định là outliers.
Lưu ý: trên thực tế, các giá trị outliers có khả năng không phải là giá trị Extreme. Nhất là so với các mảng tài liệu nhiều hơn 1 chiều.
Bạn nào tò mò các phương pháp khác thì có thể vào hỏi Google hoặc xem tại blog này
Okay, trước lúc đi vào hướng dẫn các tìm và loại bỏ outliers, các bạn cùng xem một báo cáo giải trình mẫu do mình thiết kế trên Tableau để sở hữu thể hình dung ra được những Outliers là thế nào.
Giải trình mẫu về loại bỏ Outlier trên Tableau
Sử dụng báo cáo giải trình này thế nào:
- Các chúng ta cũng có thể rê chuột trên các giá trị để sở hữu thể thấy được những giá trị outliers.
- So sánh sự khác nhau giữa giá trị trung bình mỗi hóa đơn trước và sau khoản thời gian loại bỏ Outliers.
- Kiểm soát và điều chỉnh giá trị phía trên góc phải để thấy được sự thay đổi của Outliers. Các các bạn sẽ hiểu những biến này ở phần sau của nội dung bài viết.
- Comment phía dưới xem bạn đã tìm được insight gì hay từ report này?
- Đổi quyết sách Smartphone sang ngang (landscape) nếu không thấy rõ số liệu
- Boxplot trong hình chỉ để mục tiêu so sánh vì phương pháp tính khác nhau
Các chúng ta cũng có thể tải Workbook này xuống để tham khảo cách làm. Nếu có nhiều yêu cầu mình sẽ làm bài mới hướng dẫn từng bước cách làm một chiếc tương tự như vậy.
Okay giờ mình vào phần tiếp theo xem phương pháp xác định Outliers nhé
Các bước cần thực hiện để xác định Outliers
Như tôi đã nói phía trên, trong bài này tất cả chúng ta sẽ xác định outliers là những order có mức giá trị cao hoặc thấp hơn thất thường so với những orders còn sót lại trong nhóm. Để làm điều này tất cả chúng ta thực hiện những bước sau. Tùy theo từng môi trường xung quanh tất cả chúng ta sẽ sở hữu cách khác nhau để thực hiện từng bước, nhưng cơ bản tất cả chúng ta sẽ đều trải qua những bước này.
Bước 0: Visualise/plot your data
Phác họa tài liệu lên. Đây là cách nhanh nhất để phát hiện xem tài liệu của bạn có xuất hiện Outliers hay là không (dashboard phía trên đây là ví dụ). Nếu như tài liệu của bạn hoàn toàn thường nhật thì bạn không cần thiết phải thêm gì nữa. Nếu có tín hiệu thất thường thì tiếp tục nhé.
Bước 1: Tìm tổng kinh phí của mỗi order. Các chúng ta cũng có thể thay đổi giá trị cần tính tùy thuộc vào dataset mà các bạn thao tác làm việc. Ví dụ như số lượng khách hàng mới hay số lượng hợp đồng được ký trong thời gian ngày,…
Bước 2: Tính Average & Standard Deviation
Tính giá trị trung bình (Average/Mean) và độ lệch chuẩn (Standard Deviation) của tổng kinh phí order theo từng Sub-Category. Việc tính 2 giá trị này sẽ cho tất cả chúng ta giá trị trung tâm (Average) và từ giá trị trung tâm tất cả chúng ta sẽ kiểm tra xem độ phân tán của tài liệu thế nào dựa trên giá trị của độ lệch chuẩn (Standard Deviation).

Với bộ tài liệu có độ phân tán thường nhật thì với 3 Standard Deviation (STD), tất cả chúng ta sẽ phủ rộng được khoảng tầm >99% của tài liệu. Vậy nên những tài liệu nằm ngoài 3 STD thường sẽ là Outliers.
Các bạn xem thêm về Standard Deviation ở đây nhé
Bước 3: Tính giá trị biên Upper/Lower whisker
Upper/lower whisker là 2 giá trị cực to/tiểu nhằm giúp tất cả chúng ta xác định tài liệu chuẩn (expected) và giá ngoại lai (outliers). Giá trị biên phía ngọn (upper whisker) và gốc (lower whisker) theo công thức sau:
Upper_whisker = AVG + STDV*Steps
Lower_whisker = AVG – STDV*Steps
Steps: ở đây là một dãy số tự nhiên tất cả chúng ta tự nêu ra tùy theo độ phân tán của tài liệu. Trong phần lớn trường hợp, Steps = 3 (tương đương 3 Standard deviations) sẽ phủ rộng tầm trên 90% tổng số tài liệu. Các chúng ta cũng có thể khai mạc với Step = 3 trong phần lớn trường hợp.
Bước 4: Xác định outliers dựa trên giá trị biên
Việc này khá đơn giản, tất cả chúng ta chỉ có thực hiện so sánh giá trị của Order với Upper whisker và Lower whisker. Nếu giá trị của Order nằm bên cạnh trong đoạn từ Upper đến lower thì sẽ là expected data, còn ngoài ra sẽ là outliers. Mình có công thức sau:
Xem Thêm : "Màu Xanh Da Trời" trong tiếng anh: Định nghĩa, ví dụ.
If Sum_sale > Upper_whisker or Sum_sale < Lower_whiske
then ‘Outlier’ else ‘Expected’
Như xác định phía trên là mọi giá trị nằm ngoài vùng biên đều là outliers.
Bước 5: Thực hiện tính toán khi đã loại bỏ Outliers
Thời điểm này tất cả chúng ta đã biết được những order nào là Outliers. Bước tiếp theo đơn giản là thực hiện các phép tính cấp thiết với điều kiện kèm theo để loại outliers.
Ở đây mình sẽ thực hiện lại việc tính giá trị trung bình của mỗi hóa đơn tại mỗi State.
Bước 6: Kiểm tra và kiểm soát và điều chỉnh giá trị Step
Sau thời điểm đã đã đoạt kết quả mới, tất cả chúng ta thực hiện việc so sánh với kết quả trước đó xem sự khác nhau thế nào. Lúc này tất cả chúng ta cũng cần được quan tâm đến một giá trị khác nữa là số lượng tài liệu mà tất cả chúng ta còn sót lại sau khoản thời gian loại bỏ Outliers.
Việc này cực kỳ quan trọng cho kết quả cuối cùng. Tùy thuộc vào mục tiêu sử dụng mà tất cả chúng ta chọn giá trị khác nhau.
Lúc này các bạn thực hiện tính tổng số lượng data (order) còn sót lại so với tài liệu gốc là bao nhiêu. Với số lượng tài liệu như vậy đã đủ chưa hay quá nhiều?
Nếu muốn tăng số lượng tài liệu thì tất cả chúng ta tăng giá trị của steps lên và trái lại. Mình khuyến khích là mỗi lần nên tăng/giảm đi 0.5. Sau đó tất cả chúng ta quay trở về bước 3 và tái diễn cho tới lúc có bạn cảm thấy hài lòng.
Hướng dẫn xác định và loại bỏ outliers bằng SQL
Thời điểm này các độc giả đoạn mã phía dưới nhé. Lưu ý, trong phần mình mình sử dụng SQL CTE (lệnh with). Bạn nào chưa hiểu về lệnh này thì đọc bài trước của mình tại link này nhé.
– Bước 0: tôi đã làm với Tableau dashboard phía – trên rồi nên mình không quan tâm ở đây – Bước 1: Tổng kinh phí mỗi order with sales_per_order as ( select Order_ID , state , sum(Sales) as total_order_sales from superstore.orders group by Order_ID, state ) – Bước 2: Tính avg và standard deviation – dựa trên total_order_sales và State , avg_std as ( select state ,sum(total_order_sales) as sum_sales ,count(*) as number_of_orders ,avg(total_order_sales) as avg_sales ,std(total_order_sales) as std_sales from sales_per_order group by state ) – Bước 3: tính Upper whisker và Lower whisker mỗi state – upper_whisker = avg + std*steps – lower_whisker = avg – std*steps – ở đây mình mặc đinh steps = 3 , upper_lower_whisker as ( select state , std_sales , avg_sales , number_of_orders , (avg_sales + std_sales*3) as upper_whisker – tất cả chúng ta đang kiểm tra giá trị của mỗi order – nên những giá trị <0 đều sẽ là lỗi , case when (avg_sales – std_sales*3) < 0 then 0 else (avg_sales – std_sales*3) end as lower_whisker from avg_std ) – Bước 4: xác định order là outliers – So sánh total_order_sales với upper và lower , find_outliers as ( select spo.Order_ID , spo.state , spo.total_order_sales , ulh.number_of_orders , ulh.std_sales , ulh.avg_sales , ulh.upper_whisker , ulh.lower_whisker , case when spo.total_order_sales > ulh.upper_whisker or spo.total_order_sales < ulh.lower_whisker then ‘Outlier’ else ‘Expected’ end as Outlier_status from sales_per_order as spo left join upper_lower_whisker as ulh on ulh.state = spo.state ) – Bước 5: Tính lại giá trị trung bình của mỗi order – sau khoản thời gian loại bỏ các outliers (chỉ giữ lại Expected) select state – toàn bộ order của state , number_of_orders , std_sales , upper_whisker , lower_whisker , avg_sales , avg(total_order_sales) as avg_sales_no_outliers – số order sau khoản thời gian đã loại bỏ outliers , count(*) as new_number_of_orders – tỉ lệ phần trăm tài liệu còn sót lại , count(*)/number_of_orders*100 as remaining_data from find_outliers where outlier_status = ‘Expected’ group by state,number_of_orders – ở đây mình thấy với Step=3 tôi đã đã đoạt phần lớn tài liệu (>95%) – cộng với việc khi visualise mình thấy đã xác loại được khá nhiều outliers – vậy nên mình không thay đổi step nữa
Sau thời điểm chạy đoạn code trên các các bạn sẽ thấy được rất nhiều tiểu ban có mức giá trị trung bình mỗi hóa đơn giảm hơn rất nhiều so với bạn đầu.
Nếu đã có kết quả các chúng ta cũng có thể quay trở lại Dashboard phía trên để kiểm tra và so sánh cũng như kiểm xem những outliers đã bị loại bỏ bỏ là những order nào.
Tổng kết và thực hiện
Bài này tất cả chúng ta đã cùng nhau làm quen với khái niệm, có thể mới với một số bạn, là Outliers. Cùng với đó là những lợi ích cũng như phương pháp để xác định và loại bỏ những Outliers không mong muốn.
Tôi đã cho demo thử cách xác định outliers và loại bỏ chúng dựa trên tổng kinh phí của một Order và State. Thời điểm này các chúng ta cũng có thể thực hiện cùng với dataset đó nhưng sử dụng thắc mắc sau:
“Tính trung bình tổng kinh phí mỗi order của mỗi tháng trong năm.”
Bạn nào chưa hiểu ở đâu có thể comment phía dưới. Mình sẽ nỗ lực cố gắng trả lời nếu có thể. Bookmark lại để quay trở về khi cần nhé.
Hãy nhớ là san sẻ nếu thấy hữu ích nhé.
Nội dung bài viết thuộc quyền sở hữu của Data-fun.com

