
Chúng tôi rất vui mừng chia sẻ kiến thức sâu sắc về từ khóa B tree la gi và hi vọng rằng nó sẽ hữu ích cho các bạn đọc. Bài viết tập trung trình bày ý nghĩa, vai trò và ứng dụng của từ khóa trong việc tối ưu hóa nội dung trang web và chiến dịch tiếp thị trực tuyến. Chúng tôi cung cấp các phương pháp tìm kiếm, phân tích và chọn lọc từ khóa phù hợp, kèm theo các chiến lược và công cụ hữu ích. Hi vọng rằng thông tin chúng tôi chia sẻ sẽ giúp bạn xây dựng chiến lược thành công và thu hút lưu lượng người dùng. Cảm ơn sự quan tâm và hãy tiếp tục theo dõi blog của chúng tôi để cập nhật kiến thức mới nhất.
Nội dung bài viết được dịch từ nguồn: https://dev.mysql.com/doc/refman/5.7/en/mysql-indexes.html http://www.geeksforgeeks.org/b-tree-set-1-introduction-2/
Bạn Đang Xem: Một ít về B-Tree
Như ta đã biết Index hỗ trợ cho MySql tìm kiếm các bản ghi nhanh chóng, có thể hiểu nôm na Index như phần mục lục trong một quyển sách, nhờ đó ta có thể tìm kiếm nội dung cấp thiết thông qua phần mục lục thay vì lật rở cả cuốn sách.
Index được MySql lưu giữ tại B-Trees, trong vài trường hợp ngoại lệ, có thể được lưu tại R-Trees. Vậy B-Trees là gì và được cấu trúc thế nào.
Introduction
B-Tree là cây tìm kiếm tự cân bằng. Trong hồ hết các cây tìm kiếm tự cân bằng khác (như AVL và Red Black Trees), giả thiết rằng mọi thứ đều nằm trong bộ nhớ chính. Để hiểu được việc sử dụng B-Trees, tất cả chúng ta phải nghĩ đến số lượng tài liệu khổng lồ mà không thể lưu trong bộ nhớ chính. Khi số lượng keys lớn, tài liệu được đọc từ hard disk dưới dạng khối (blocks). Thời kì đọc tài liệu từ hard disk rất mất thời gian so với thời kì truy xuất bộ nhớ chính, Ý tưởng chính của việc sử dụng B-Trees là giảm số lần truy cập đĩa. Hồ hết các hoạt động sinh hoạt của cây (tìm kiếm, chèn, xóa, max, min, ..etc) yêu cầu truy cập đĩa O (h) đây chính là độ cao của B-Trees. B-Trees là fat trees. Độ cao của cây B được hạn chế tối đa bằng việc bố trí nhiều nhất keys tại những node. Nói chung kích thước node tương đương kích thước block. Vì khả năng hạn chế h, tổng số lần đĩa truy cập cho hồ hết các hoạt động sinh hoạt được giảm đáng kể so với Cây tìm kiếm cân bằng nhị phân như cây AVL, Red Black Tree, ..etc.
Tính chất của B-Tree
- Tất cả lá ở cùng cấp.
- Một B-Tree được xác định bằng thuật ngữ tối thiểu ‘t’. Giá trị của t phụ thuộc vào kích thước khối đĩa.
- Mỗi node trừ root phải chứa ít nhất t-1 keys. Gốc có thể chứa tối thiểu 1 node.
- Tất cả những node (gồm có cả gốc) có thể chứa nhiều nhất 2t – 1 keys.
- Số con của một node bằng số keys trong đó cộng với cùng 1.
- Tất cả những keys của một node được sắp xếp theo trật tự ngày càng tăng. Child giữa hai keys k1 và k2 chứa tất cả những keys nằm trong khoảng tầm từ k1 và k2.
- B-Tree phát triển và co lại từ gốc mà không phải như cây tìm kiếm nhị phân. Cây tìm kiếm nhị phân phát triển rộng dần.
- Giống như cây tìm kiếm nhị phân cân bằng, sự phức tạp về thời kì để tìm kiếm, chèn và xóa là khá lớn.
Sau đây là một ví dụ B-Tree mức độ tối thiểu 3. Lưu ý rằng trong thực tế B-Cây, giá trị của mức độ tối thiểu là nhiều hơn 3.
Xem Thêm : Tiền vệ Box to Box là gì? Top tiền vệ box to box hay nhất
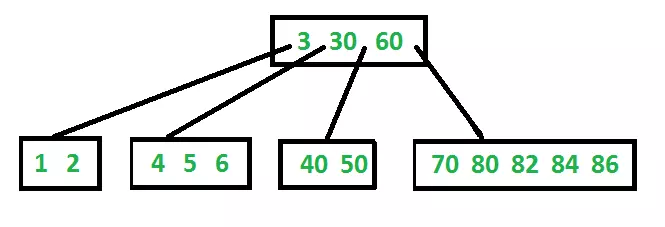
Tìm kiếm
Tìm kiếm tương tự như tìm kiếm trong Cây tìm kiếm nhị phân. Hãy tìm chìa khóa để tìm k. Tất cả chúng ta xuất phát điểm từ gốc và đệ quy đi qua. Khi đối chiếu với mỗi node không có nhánh sẽ không còn xét đến, nếu node có key, tất cả chúng ta chỉ việc trả lại node. Nếu không, tất cả chúng ta sẽ quay trở lại child thích hợp (The child ngay trước key) của node. Nếu tất cả chúng ta đạt đến một node và không tìm thấy k trong node leaf, tất cả chúng ta sẽ trả về NULL.
Traverse
Traversal cũng tương tự như Invers traversal của cây nhị phân. Chúng tôi xuất phát điểm từ child ở bên trái, in lại các child sót lại bên trái, sau đó tái diễn quá trình tương tự cho child và key sót lại. Cuối cùng, in trái lại child đầu bên phải.
Insert
Một key mới luôn luôn được chèn vào tại node leaf. Gọi key được chèn vào là k. Giống như BST, tất cả chúng ta xuất phát điểm từ gốc và đi xuống cho tới lúc tất cả chúng ta tìm được một node leaf. Khi tất cả chúng ta tìm được một node leaf, tất cả chúng ta chèn keys vào node leaf đó. Không như BST, tất cả chúng ta có một phạm vi được xác định trước về số lượng các keys mà một node có thể chứa. Vì vậy, trước lúc chèn một key vào node, chúng tôi đảm nói rằng node có thể được add thêm key.
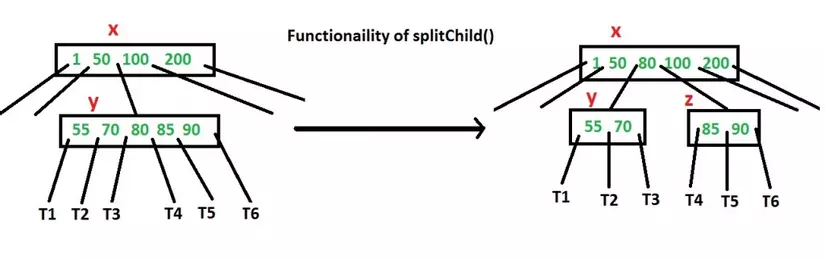
Làm thế nào để đảm nói rằng một node có không gian có sẵn cho key trước lúc key được chèn vào? Chúng tôi sử dụng một method được gọi là splitChild () được sử dụng để phân chia một child của một node. Xem biểu đồ tại chỗ này để hiểu được sự phân chia. Trong sơ đồ sau, child y của x đang rất được chia thành hai node y và z. Lưu ý rằng các method splitChild vận chuyển một key lên và đây là lý do B-Trees lớn lên không phải như BSTs phát triển.
Xem Thêm : Hãy giải thích ý nghĩa thành ngữ ếch ngồi đáy giếng. Đặt một câu có
Như đã thảo luận ở trên, để chèn một key mới, tất cả chúng ta đi từ gốc tới leaf. Trước lúc đi qua một node, trước hết tất cả chúng ta kiểm tra xem node đã đầy. Nếu node là đầy, chúng tôi chia nó để tạo không gian.
Deletion process
Xoá từ B-Trees là phức tạp hơn là chèn, bởi vì tất cả chúng ta có thể xóa một khoá từ bất kỳ node nào – không chỉ là leaf – và khi tất cả chúng ta xóa một key một node, tất cả chúng ta sẽ phải sắp xếp lại các child của node.
Như trong chèn, tất cả chúng ta phải đảm bảo xóa không vi phạm các tính chất của cây B. Cũng như tất cả chúng ta phải đảm nói rằng một node không bị quá rộng do chèn, tất cả chúng ta phải đảm nói rằng một node không thật nhỏ trong quá trình xóa (ngoại trừ gốc được phép có thấp hơn t-1 số tối thiểu của những keys). Cũng giống như một thuật toán chèn đơn giản có thể phải sao lưu nếu một node trên phố dẫn đến nơi keys được chèn vào đầy đủ, một cách tiếp cận đơn giản để xóa có thể phải sao lưu nếu một node (khác với gốc) dọc theo đường dẫn đến nơi key được xóa sẽ sở hữu được số keys tối thiểu.
Delete method xóa k khỏi cây con được bắt nguồn từ x. Method này đảm nói rằng bất kì khi nào nó tự gọi mình một cách đệ quy trên một nút x, số keý trong x ít nhất là mức tối thiểu t. Lưu ý rằng tham dự này yên cầu một keys quan trọng hơn mức tối thiểu yêu cầu bởi tham dự cây B thông thường, do đó thỉnh thoảng một keys có thể phải được vận chuyển vào một trong những child node trước lúc đệ quy child đó. Điều kiện kèm theo được tăng cường này được chấp nhận tất cả chúng ta xóa một key cây mà không cần thiết phải “sao lưu” (với một ngoại lệ, tất cả chúng ta sẽ giảng giải). Bạn nên giảng giải các đặc tả sau để xóa từ cây B với sự hiểu biết rằng nếu node gốc x trở thành node bên trong không có keys (tình huống này còn có thể xẩy ra trong trường hợp 2c và 3b sau đó tất cả chúng ta xóa x, và x chỉ có con x .c1 trở thành gốc mới của cây, giảm độ cao của cây bằng một cây và dữ gìn và bảo vệ tài sản mà gốc của cây chứa ít nhất một keys (trừ khi cây trống).
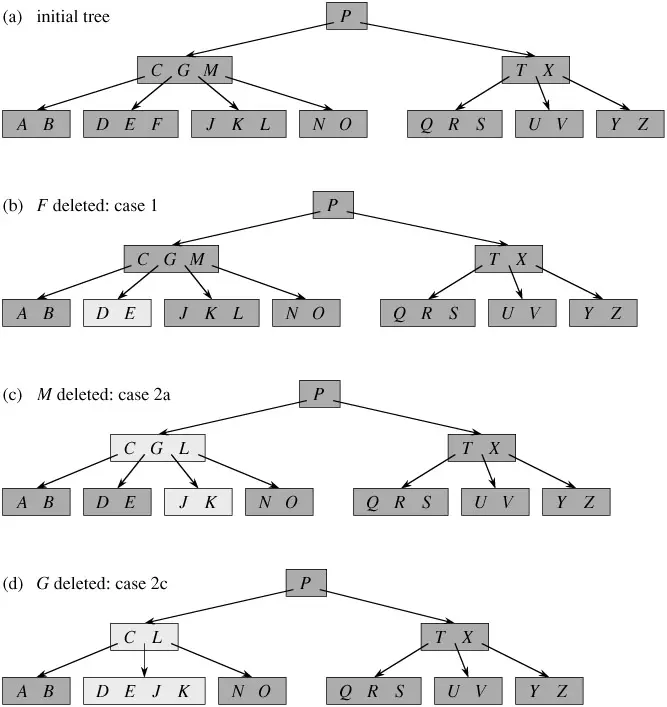
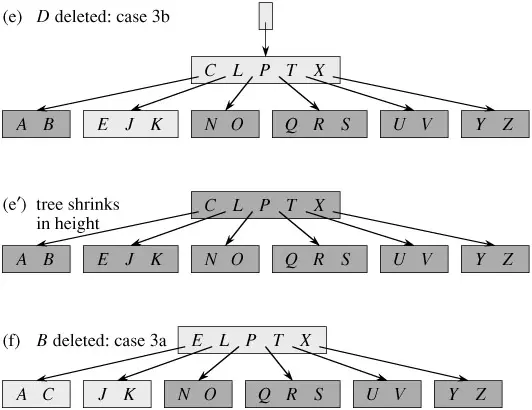
Để làm rõ hơn về các thuật toán sử dụng trong B-Trees cần có thêm tìm hiểu khác.
Cảm ơn và hi vọng nội dung bài viết có ích trong công việc của bạn.

