
Chúng tôi vui mừng chia sẻ kiến thức về từ khóa Optimizer la gi để tối ưu hóa nội dung trang web và tiếp thị trực tuyến. Bài viết cung cấp phương pháp tìm kiếm, phân tích từ khóa và chiến lược hiệu quả. Cảm ơn sự quan tâm và hãy tiếp tục theo dõi để cập nhật kiến thức mới.
Có thể bạn quan tâm
- Excel Binary Workbook Là Gì, Khi Nào Nên Sử Dụng Định Dạng Xlsm Hoặc Xlsb
- Hoàn lưu bão là gì? Mức độ tàn phá nghiêm trọng sau bão
- Ca Trưởng Ca Tiếng Anh Là Gì, Chức Danh Trong Công Ty Bằng Tiếng Anh
- Windows 10 Redstone 4: Tính năng mới và những thay đổi nào đang chờ bạn?
- Đêm tân hôn, quan hệ bao nhiêu lần là đủ?
Chào các bạn, hôm nay mình sẽ trình bày về optimizer. Vậy optimizer là gì ?, để trả lời thắc mắc đó thì những bạn phải trả lời được những thắc mắc sau đây :
Bạn Đang Xem: Optimizer- Hiểu sâu về các thuật toán tối ưu ( GD,SGD,Adam,..)
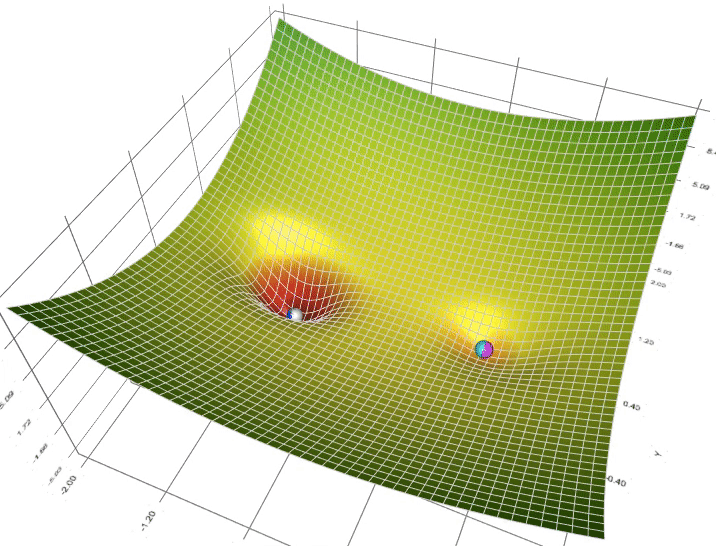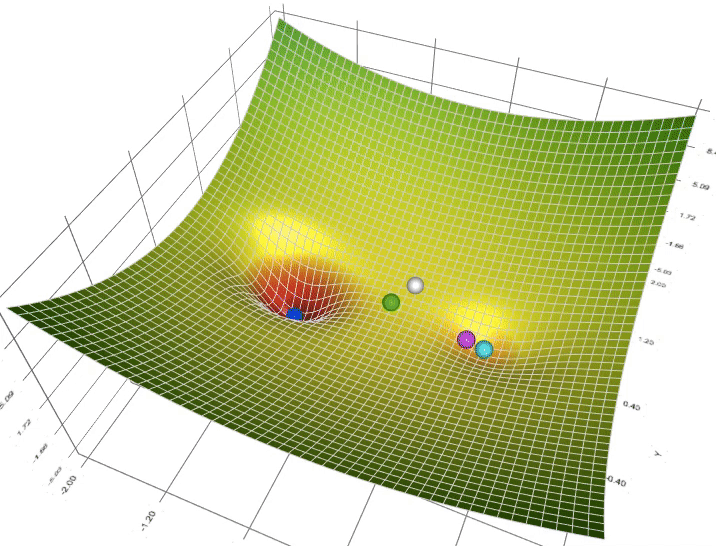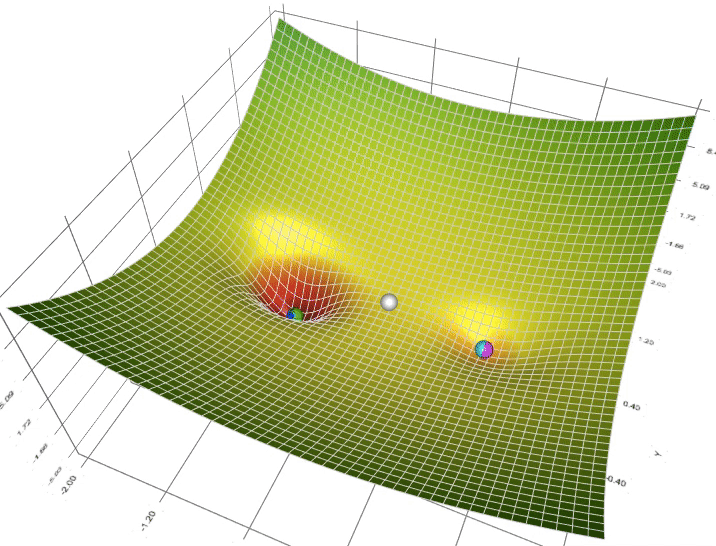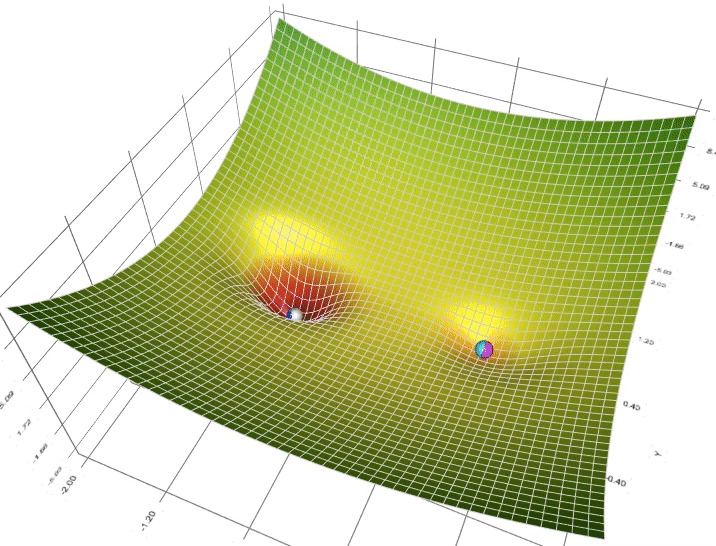
- Optimizer là gì ?
- Ứng dụng của nó ra sao, vì sao phải dùng nó ?
- Các thuật toán tối ưu, ưu nhược điểm của mỗi thuật toán, thuật toán tối ưu này hơn thuật toán kia ở điểm nào ?
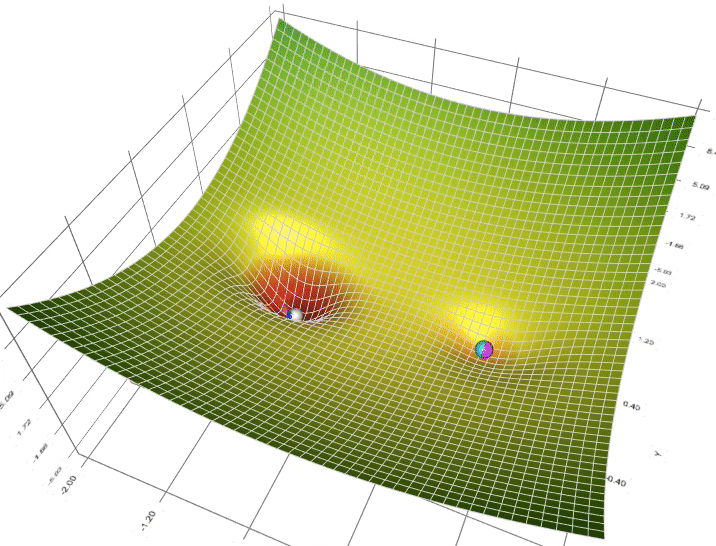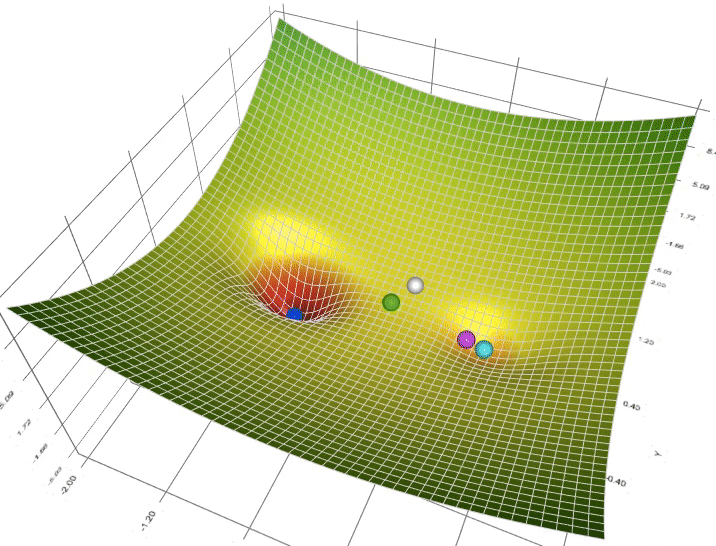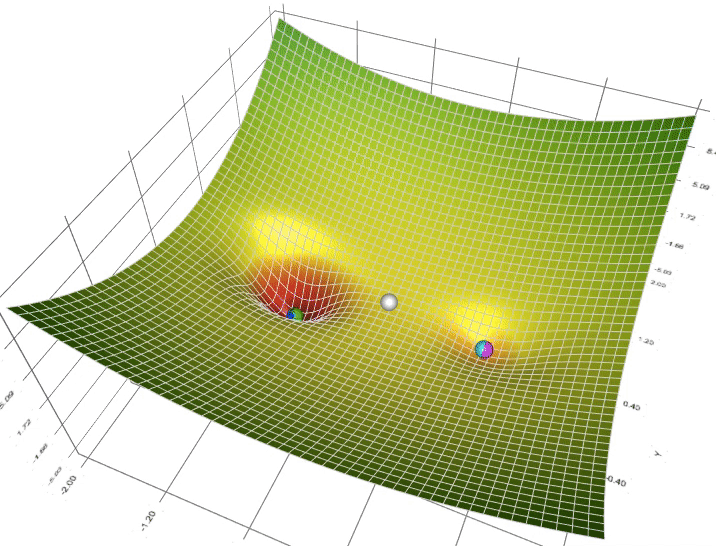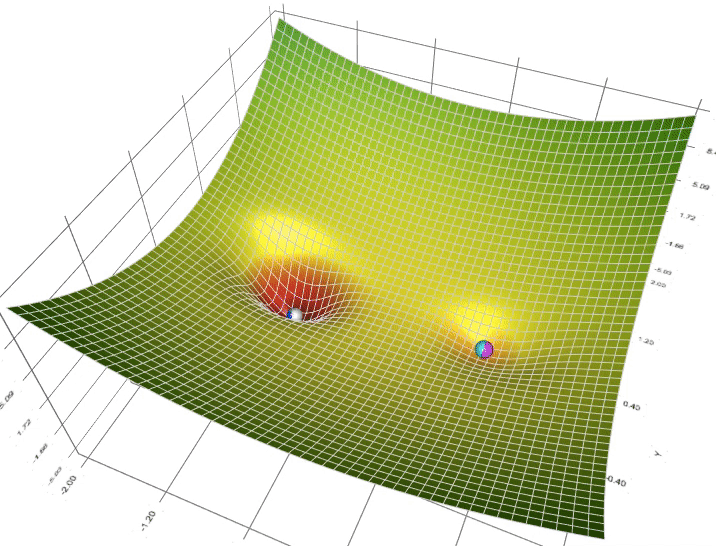
- Khi nào nên ứng dụng optimizer này , khi nào nên ứng dụng cái kia?
Xem Thêm : Kwai là gì? Cách chơi và kiếm tiền từ Kwai mới nhất
Nội dung bài hôm nay mình sẽ giảng giải rõ ràng về optimizers theo bố cục tổng quan trả lời các thắc mắc trên. Nội dung bài viết này sẽ không còn nặng về phần tính toán, code, mình sẽ dùng ví dụ trực quan để minh họa cho dễ hiểu.
Optimizer là gì, vì sao phải dùng nó?
Trước lúc đi sâu vào việc thì tất cả chúng ta cần hiểu thế nào là thuật toán tối ưu (optimizers).Về cơ bản, thuật toán tối ưu là cơ sở để xây dựng mô hình neural network với mục tiêu “học ” được những features ( hay pattern) của tài liệu nguồn vào, từ đó có thể tìm 1 cặp weights và bias phù hợp để tối ưu hóa model. Nhưng vấn đề là “học” ra sao? Cụ thể là weights và bias được tìm ra sao! Đâu phải chỉ có random (weights, bias) 1 số lần hữu hạn và hy vọng ở một bước nào đó ta có thể tìm được lời giải. Rõ ràng là không khả thi và lãng phí tài nguyên! Tất cả chúng ta phải tìm 1 thuật toán để cải thiện weight và bias theo từng bước, và đó là lý do các thuật toán optimizer ra đời.
Các thuật toán tối ưu ?
1. Gradient Descent (GD)
Trong các bài toán tối ưu, tất cả chúng ta thường tìm giá trị nhỏ nhất của một hàm số nào đó, mà hàm số đạt giá trị nhỏ nhất lúc đạo hàm bằng 0. Nhưng đâu phải lúc nào đạo hàm hàm số cũng được, khi đối chiếu với các hàm số nhiều biến thì đạo hàm rất phức tạp, thậm chí còn là bất khả thi. Nên thay vào đó người ta tìm điểm gần với điểm cực tiểu nhất và xem đó là nghiệm bài toán. Gradient Descent dịch ra tiếng Việt là giảm dần độ dốc, nên hướng tiếp cận ở đây là chọn một nghiệm tình cờ cứ sau mỗi vòng lặp (hay epoch) thì cho nó tiến dần tới điểm cần tìm. Công thức : xnew = xold – learningrate.gradient(x) Đặt thắc mắc vì sao có công thức đó ? Công thức trên được xây dựng để update lại nghiệm sau mỗi vòng lặp . Dấu ‘-‘ trừ ở đây ám chỉ ngược hướng đạo hàm. Đặt tiếp thắc mắc vì sao lại ngược hướng đạo hàm ? Ví dụ như khi đối chiếu với hàm f(x)= 2x +5sin(x) như hình dưới thì f'(x) =2x + 5cos(x) với x_old =-4 thì f'(-4) <0 => x_new > x_old nên nghiệm sẽ vận chuyển về bên phải tiến gần tới điểm cực tiểu. trái lại với x_old =4 thì f'(4) >0 => x_new <x_old nên nghiệm sẽ vận chuyển về bên trái tiến gần tới điểm cực tiểu.a) Gradient cho hàm 1 biến :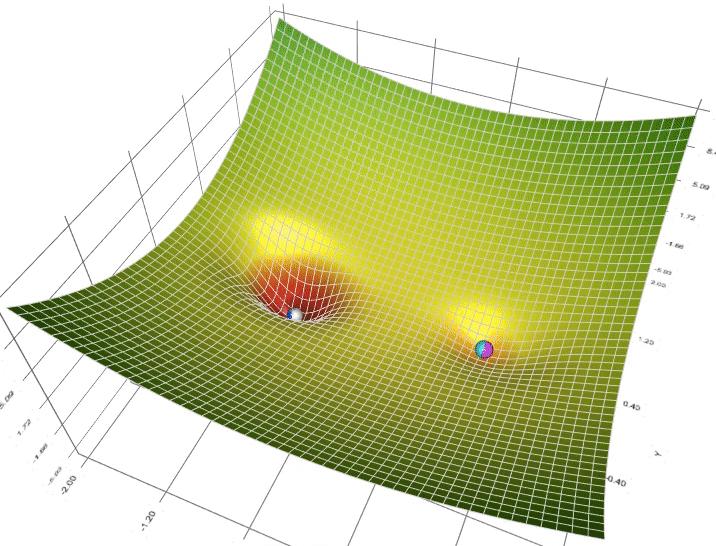
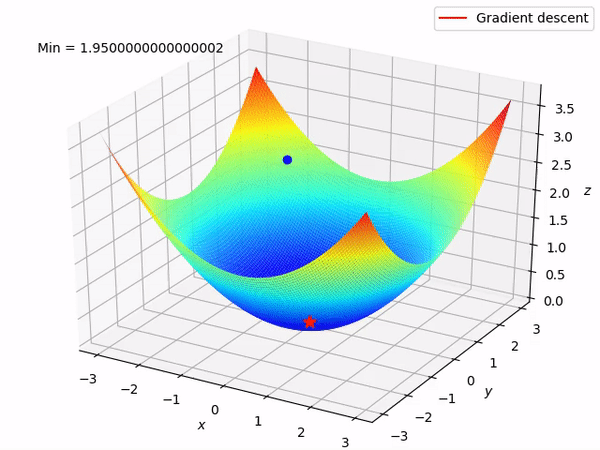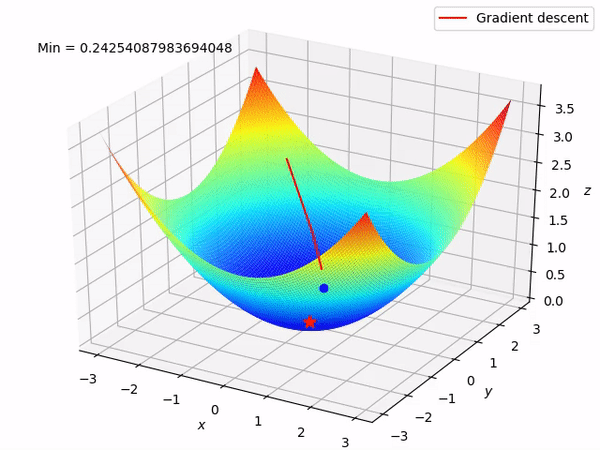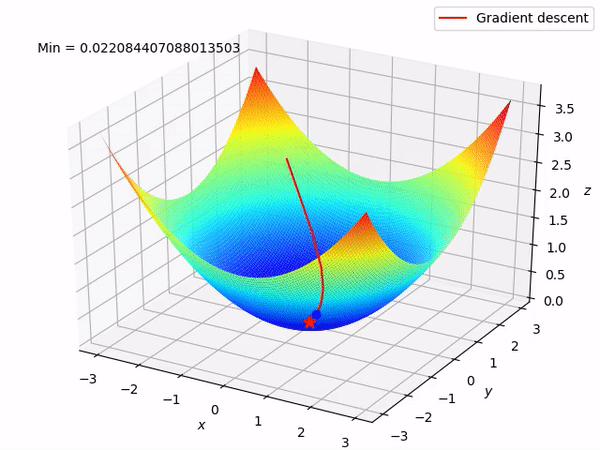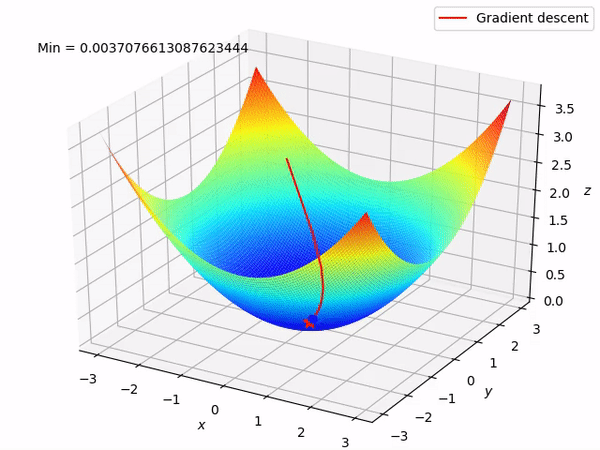
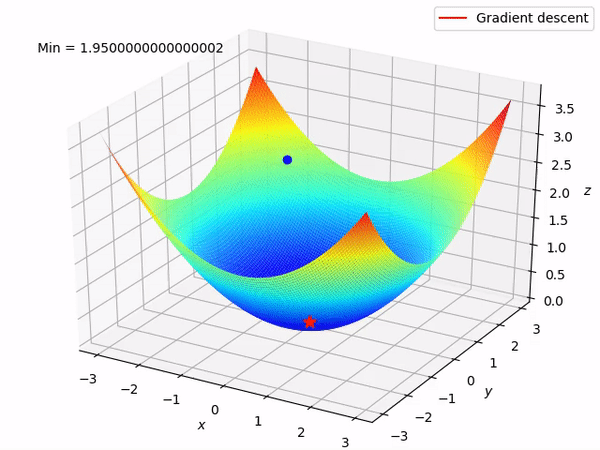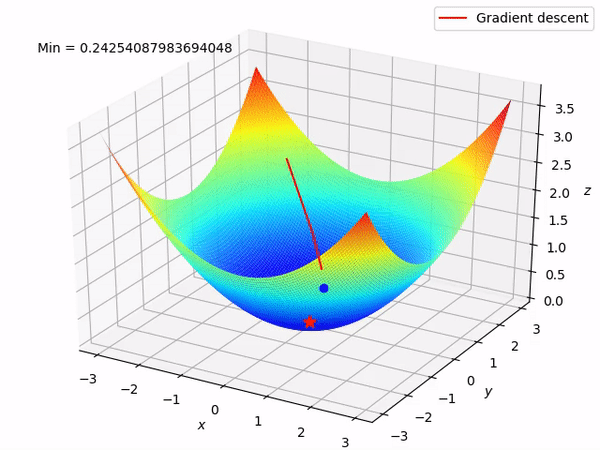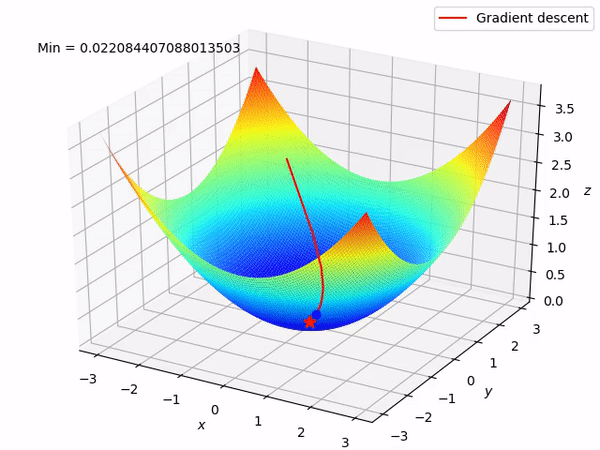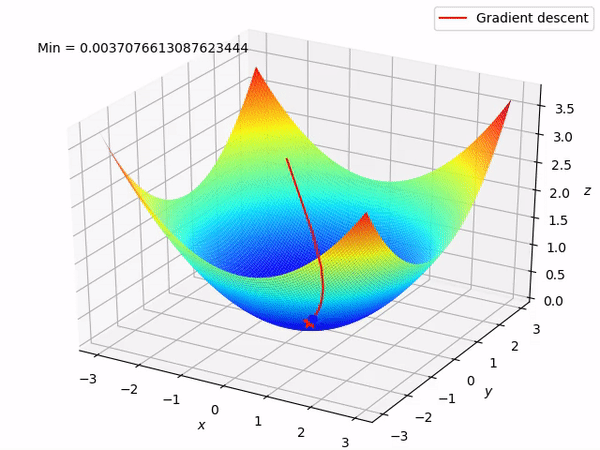 Nguồn : https://machinelearningcoban.com/2017/01/12/gradientdescent/ Qua các hình trên ta thấy Gradient descent phụ thuộc vào nhiều yếu tố : như nếu tìm điểm x lúc đầu khác nhau sẽ tác động đến quá trình quy tụ; hoặc tốc độ học (learning rate) quá rộng hoặc quá nhỏ cũng tác động: nếu tốc độ học quá nhỏ thì tốc độ quy tụ rất chậm tác động đến quá trình training, còn tốc độ học quá rộng thì tiến nhanh tới đích sau vài vòng lặp tuy nhiên thuật toán không quy tụ, quanh quẩn quanh đích vì bước nhảy quá rộng.b) Gradient descent cho hàm nhiều biến :Ưu điểm :
Nguồn : https://machinelearningcoban.com/2017/01/12/gradientdescent/ Qua các hình trên ta thấy Gradient descent phụ thuộc vào nhiều yếu tố : như nếu tìm điểm x lúc đầu khác nhau sẽ tác động đến quá trình quy tụ; hoặc tốc độ học (learning rate) quá rộng hoặc quá nhỏ cũng tác động: nếu tốc độ học quá nhỏ thì tốc độ quy tụ rất chậm tác động đến quá trình training, còn tốc độ học quá rộng thì tiến nhanh tới đích sau vài vòng lặp tuy nhiên thuật toán không quy tụ, quanh quẩn quanh đích vì bước nhảy quá rộng.b) Gradient descent cho hàm nhiều biến :Ưu điểm : 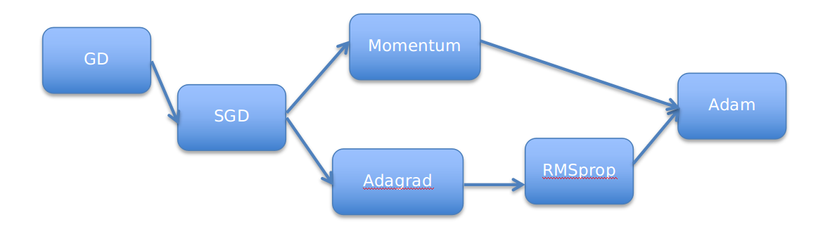 Thuật toán gradient descent cơ bản, dễ hiểu. Thuật toán đã giải quyết và xử lý được vấn đề tối ưu model neural network bằng phương pháp update trọng số sau mỗi vòng lặp.Nhược điểm : Vì đơn giản nên thuật toán Gradient Descent còn nhiều hạn chế như phụ thuộc vào nghiệm khởi tạo lúc đầu và learning rate. Ví dụ 1 hàm số có 2 global minimum thì tùy thuộc vào 2 điểm khởi tạo lúc đầu sẽ cho ra 2 nghiệm cuối cùng khác nhau. Tốc độ học quá rộng sẽ làm cho thuật toán không quy tụ, quanh quẩn bên đích vì bước nhảy quá rộng; hoặc tốc độ học nhỏ tác động đến tốc độ training
Thuật toán gradient descent cơ bản, dễ hiểu. Thuật toán đã giải quyết và xử lý được vấn đề tối ưu model neural network bằng phương pháp update trọng số sau mỗi vòng lặp.Nhược điểm : Vì đơn giản nên thuật toán Gradient Descent còn nhiều hạn chế như phụ thuộc vào nghiệm khởi tạo lúc đầu và learning rate. Ví dụ 1 hàm số có 2 global minimum thì tùy thuộc vào 2 điểm khởi tạo lúc đầu sẽ cho ra 2 nghiệm cuối cùng khác nhau. Tốc độ học quá rộng sẽ làm cho thuật toán không quy tụ, quanh quẩn bên đích vì bước nhảy quá rộng; hoặc tốc độ học nhỏ tác động đến tốc độ training
2. Stochastic Gradient Descent (SGD)
Stochastic là 1 trong những biến thể của Gradient Descent . Thay vì sau mỗi epoch tất cả chúng ta sẽ update trọng số (Weight) 1 lần thì trong mỗi epoch có N điểm tài liệu tất cả chúng ta sẽ update trọng số N lần. Nhìn vào một mặt , SGD sẽ làm giảm đi tốc độ của một epoch. Tuy nhiên nhìn theo một phía khác,SGD sẽ quy tụ rất nhanh chỉ với sau vài epoch. Công thức SGD cũng tương tự như GD nhưng thực hiện trên từng điểm tài liệu. 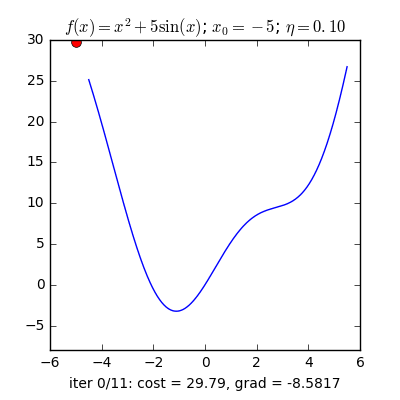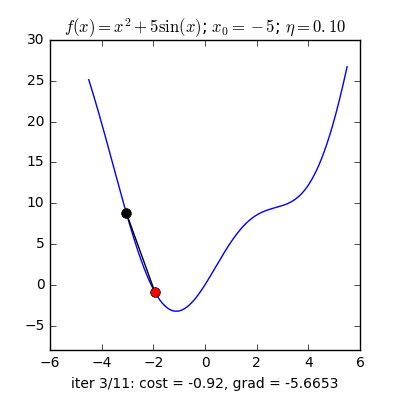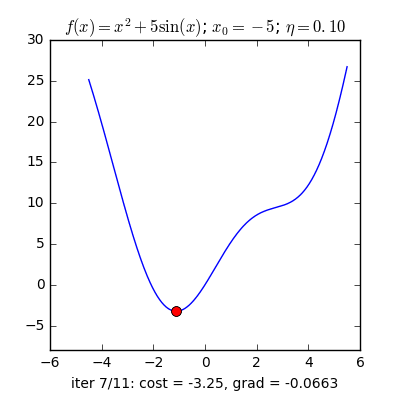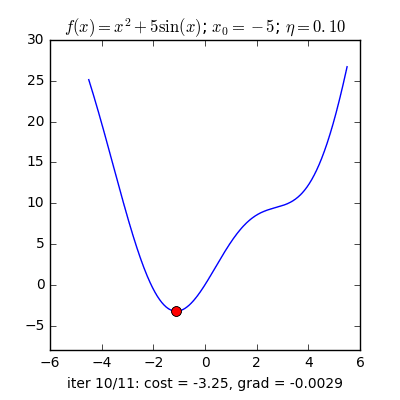 Nhìn vào 2 hình trên, ta thấy SGD có lối đi khá là zig zắc , không mượt như GD. Dễ hiểu điều đó vì 1 điểm tài liệu không thể đại diện thay mặt cho toàn bộ tài liệu. Đặt thắc mắc vì sao phải dùng SGD thay cho GD mặt dù lối đi của nó khá zig zắc ? Ở đây, GD có hạn chế khi đối chiếu với cơ sở tài liệu lớn ( vài triệu tài liệu ) thì việc tính toán đạo hàm trên toàn bộ tài liệu qua mỗi vòng lặp trở thành kềnh càng. Không chỉ vậy GD không phù phù hợp với trực tuyến learning. Vậy trực tuyến learning là gì? trực tuyến learning là lúc tài liệu update liên tục (ví dụ như thêm người dùng đăng kí ) thì mỗi lần thêm tài liệu ta phải tính lại đạo hàm trên toàn bộ tài liệu => thời kì tính toán lâu, thuật toán không trực tuyến nữa. Vì thế SGD ra đời để giải quyết và xử lý vấn đề đó, vì mỗi lần thêm tài liệu mới vào chỉ có update trên 1 điểm tài liệu đó thôi, phù phù hợp với trực tuyến learning. Một ví dụ minh hoạ : có 10.000 điểm tài liệu thì chỉ với sau 3 epoch ta đã đã đạt nghiệm tốt, còn với GD ta phải dùng tới 90 epoch để đạt được kết quả đó.Ưu điểm : Thuật toán giải quyết và xử lý được khi đối chiếu với cơ sở tài liệu lớn mà GD không làm được. Thuật toán tối ưu này hiên nay vẫn hay được sử dụng.Nhược điểm : Thuật toán vẫn chưa giải quyết và xử lý được 2 nhược điểm lớn của gradient descent ( learning rate, điểm tài liệu lúc đầu ). Vì vậy ta phải phối hợp SGD với một số thuật toán khác ví như: Momentum, AdaGrad,..Các thuật toán này sẽ tiến hành trình bày ở phần sau.
Nhìn vào 2 hình trên, ta thấy SGD có lối đi khá là zig zắc , không mượt như GD. Dễ hiểu điều đó vì 1 điểm tài liệu không thể đại diện thay mặt cho toàn bộ tài liệu. Đặt thắc mắc vì sao phải dùng SGD thay cho GD mặt dù lối đi của nó khá zig zắc ? Ở đây, GD có hạn chế khi đối chiếu với cơ sở tài liệu lớn ( vài triệu tài liệu ) thì việc tính toán đạo hàm trên toàn bộ tài liệu qua mỗi vòng lặp trở thành kềnh càng. Không chỉ vậy GD không phù phù hợp với trực tuyến learning. Vậy trực tuyến learning là gì? trực tuyến learning là lúc tài liệu update liên tục (ví dụ như thêm người dùng đăng kí ) thì mỗi lần thêm tài liệu ta phải tính lại đạo hàm trên toàn bộ tài liệu => thời kì tính toán lâu, thuật toán không trực tuyến nữa. Vì thế SGD ra đời để giải quyết và xử lý vấn đề đó, vì mỗi lần thêm tài liệu mới vào chỉ có update trên 1 điểm tài liệu đó thôi, phù phù hợp với trực tuyến learning. Một ví dụ minh hoạ : có 10.000 điểm tài liệu thì chỉ với sau 3 epoch ta đã đã đạt nghiệm tốt, còn với GD ta phải dùng tới 90 epoch để đạt được kết quả đó.Ưu điểm : Thuật toán giải quyết và xử lý được khi đối chiếu với cơ sở tài liệu lớn mà GD không làm được. Thuật toán tối ưu này hiên nay vẫn hay được sử dụng.Nhược điểm : Thuật toán vẫn chưa giải quyết và xử lý được 2 nhược điểm lớn của gradient descent ( learning rate, điểm tài liệu lúc đầu ). Vì vậy ta phải phối hợp SGD với một số thuật toán khác ví như: Momentum, AdaGrad,..Các thuật toán này sẽ tiến hành trình bày ở phần sau.
3. Momentum
Xem Thêm : Hình ảnh siêu âm bóc tách túi thai: Có thực sự nguy hiểm?
Để khắc phục các hạn chế trên của thuật toán Gradient Descent người ta dùng gradient descent with momentum. Vậy gradient with momentum là gì ?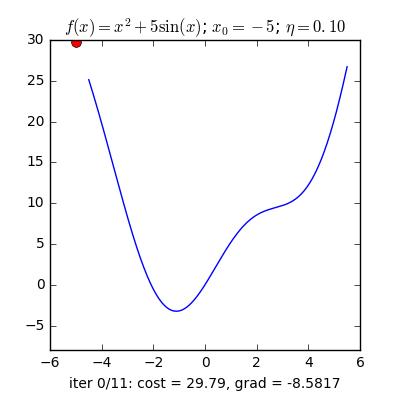 Nguồn: https://machinelearningcoban.com/2017/01/16/gradientdescent2/ Để giảng giải được Gradient with Momentum thì trước tiên ta nên nhìn dưới góc độ vật lí: Như hình b phía trên, nếu ta thả 2 viên bi tại 2 điểm khác nhau A và B thì viên bị A sẽ trượt xuống điểm C còn viên bi B sẽ trượt xuống điểm D, nhưng ta lại không mong muốn viên bi B sẽ dừng ở điểm D (local minimum) mà sẽ tiếp tục lăn tới điểm C (global minimum). Để thực hiện được điều đó ta phải cấp cho viên bi B 1 véc tơ vận tốc tức thời lúc đầu đủ lớn để nó có thể vượt qua điểm E tới điểm C. Dựa vào ý tưởng này người ta xây hình thành thuật toán Momentum ( tức là theo đà tiến tới ). Nhìn dưới góc độ toán học, ta có công thức Momentum:xnew = xold -(gama.v + learningrate.gradient) Trong số đó : xnew: tọa độ mới xod : tọa độ cũ gama: parameter , thường =0.9 learningrate : tốc độ học gradient : đạo hàm của hàm f
Nguồn: https://machinelearningcoban.com/2017/01/16/gradientdescent2/ Để giảng giải được Gradient with Momentum thì trước tiên ta nên nhìn dưới góc độ vật lí: Như hình b phía trên, nếu ta thả 2 viên bi tại 2 điểm khác nhau A và B thì viên bị A sẽ trượt xuống điểm C còn viên bi B sẽ trượt xuống điểm D, nhưng ta lại không mong muốn viên bi B sẽ dừng ở điểm D (local minimum) mà sẽ tiếp tục lăn tới điểm C (global minimum). Để thực hiện được điều đó ta phải cấp cho viên bi B 1 véc tơ vận tốc tức thời lúc đầu đủ lớn để nó có thể vượt qua điểm E tới điểm C. Dựa vào ý tưởng này người ta xây hình thành thuật toán Momentum ( tức là theo đà tiến tới ). Nhìn dưới góc độ toán học, ta có công thức Momentum:xnew = xold -(gama.v + learningrate.gradient) Trong số đó : xnew: tọa độ mới xod : tọa độ cũ gama: parameter , thường =0.9 learningrate : tốc độ học gradient : đạo hàm của hàm f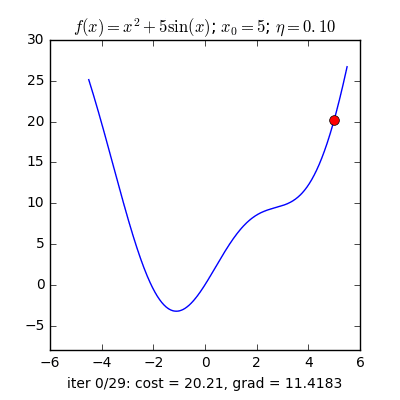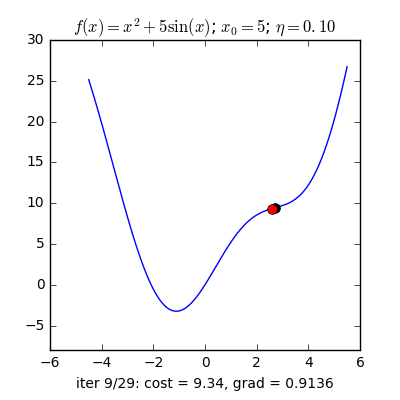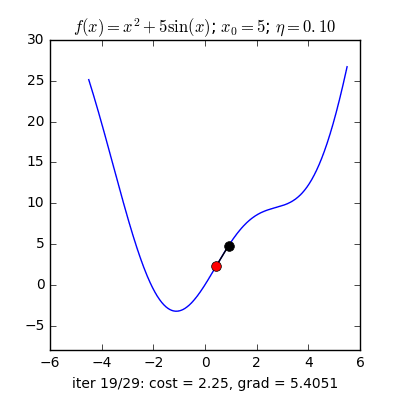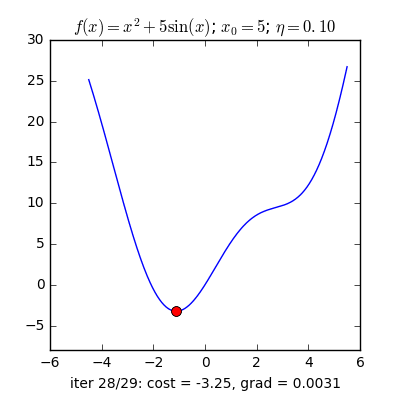 Nguồn : https://machinelearningcoban.com/2017/01/16/gradientdescent2/ Qua 2 ví dụ minh họa trên của hàm f(x) = x.2 + 10sin(x), ta thấy GD without momentum sẽ quy tụ sau 5 vòng lặp nhưng không phải là global minimum. Nhưng GD with momentum dù mất nhiều vòng lặp nhưng nghiệm tiến tới global minimum, qua hình ta thấy nó sẽ vượt tốc tiến tới điểm global minimum và dao động qua lại quanh điểm đó trước khai tạm ngừng. Ưu điểm : Thuật toán tối ưu giải quyết và xử lý được vấn đề: Gradient Descent không tiến được tới điểm global minimum mà chỉ tạm ngừng ở local minimum.Nhược điểm : Tuy momentum giúp hòn bi vượt dốc tiến tới điểm đích, tuy nhiên khi tới gần đích, nó vẫn mất khá nhiều thời kì giao động qua lại trước lúc dừng hẳn, điều này được giảng giải vì viên bi có đà.
Nguồn : https://machinelearningcoban.com/2017/01/16/gradientdescent2/ Qua 2 ví dụ minh họa trên của hàm f(x) = x.2 + 10sin(x), ta thấy GD without momentum sẽ quy tụ sau 5 vòng lặp nhưng không phải là global minimum. Nhưng GD with momentum dù mất nhiều vòng lặp nhưng nghiệm tiến tới global minimum, qua hình ta thấy nó sẽ vượt tốc tiến tới điểm global minimum và dao động qua lại quanh điểm đó trước khai tạm ngừng. Ưu điểm : Thuật toán tối ưu giải quyết và xử lý được vấn đề: Gradient Descent không tiến được tới điểm global minimum mà chỉ tạm ngừng ở local minimum.Nhược điểm : Tuy momentum giúp hòn bi vượt dốc tiến tới điểm đích, tuy nhiên khi tới gần đích, nó vẫn mất khá nhiều thời kì giao động qua lại trước lúc dừng hẳn, điều này được giảng giải vì viên bi có đà.
4. Adagrad
Không giống như những thuật toán trước đó thì learning rate hầu như giống nhau trong quá trình training (learning rate là hằng số), Adagrad coi learning rate là 1 trong những thông số. Tức là Adagrad sẽ cho learning rate biến thiên sau mỗi thời khắc t.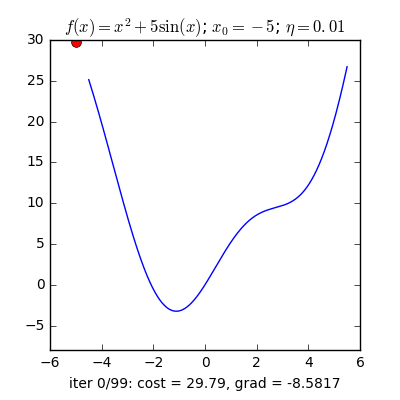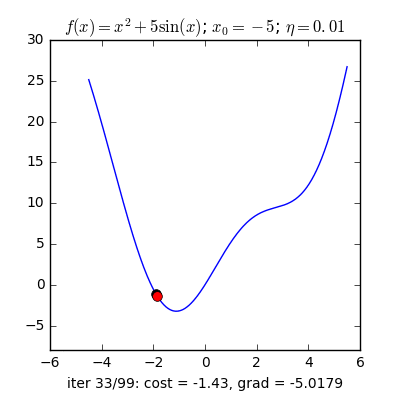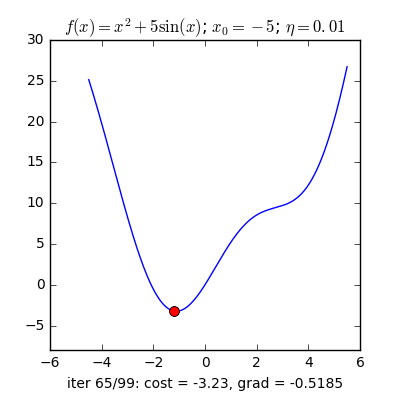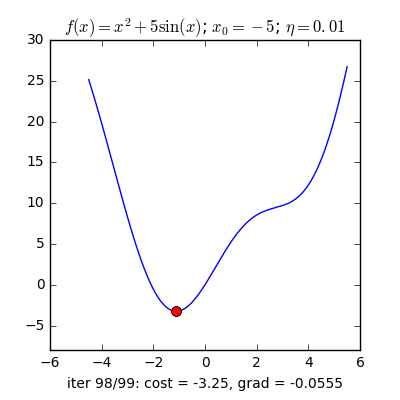 Trong số đó : n : hằng số gt : gradient tại thời khắc t ϵ : hệ số tránh lỗi ( chia cho mẫu bằng 0) G : là ma trận chéo mà mỗi thành phần trên phố chéo (i,i) là bình phương của đạo hàm vectơ thông số tại thời khắc t.Ưu điểm : Một lơi ích thường nhìn thấy của Adagrad là tránh việc kiểm soát và điều chỉnh learning rate bằng tay, chỉ có để tốc độ học default là 0.01 thì thuật toán sẽ tự động hóa kiểm soát và điều chỉnh.Nhược điểm : Yếu điểm của Adagrad là tổng bình phương biến thiên sẽ lớn dần theo thời kì cho đến lúc nó làm tốc độ học cực kì nhỏ, thao tác làm việc training trở thành tạm dừng hoạt động.
Trong số đó : n : hằng số gt : gradient tại thời khắc t ϵ : hệ số tránh lỗi ( chia cho mẫu bằng 0) G : là ma trận chéo mà mỗi thành phần trên phố chéo (i,i) là bình phương của đạo hàm vectơ thông số tại thời khắc t.Ưu điểm : Một lơi ích thường nhìn thấy của Adagrad là tránh việc kiểm soát và điều chỉnh learning rate bằng tay, chỉ có để tốc độ học default là 0.01 thì thuật toán sẽ tự động hóa kiểm soát và điều chỉnh.Nhược điểm : Yếu điểm của Adagrad là tổng bình phương biến thiên sẽ lớn dần theo thời kì cho đến lúc nó làm tốc độ học cực kì nhỏ, thao tác làm việc training trở thành tạm dừng hoạt động.
5. RMSprop
RMSprop giải quyết và xử lý vấn đề tỷ lệ học giảm dần của Adagrad bằng phương pháp chia tỷ lệ học cho trung bình của bình phương gradient.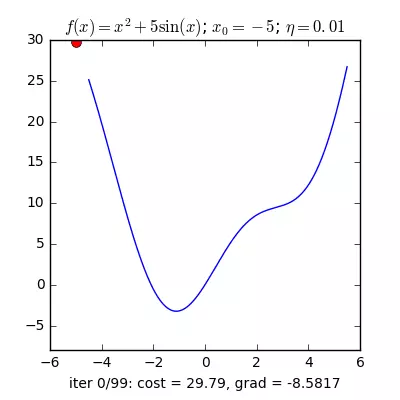 Ưu điểm : Ưu điểm rõ ràng nhất của RMSprop là giải quyết và xử lý được vấn đề tốc độ học giảm dần của Adagrad ( vấn đề tốc độ học giảm dần theo thời kì sẽ làm việc training chậm dần, có thể dẫn tới bị tạm dừng hoạt động )Nhược điểm : Thuật toán RMSprop có thể cho kết quả nghiệm chỉ là local minimum chứ không đạt được global minimum như Momentum. Vì vậy người ta sẽ phối hợp cả hai thuật toán Momentum với RMSprop cho ra 1 thuật toán tối ưu Adam. Tất cả chúng ta sẽ trình bày nó trong phần sau.
Ưu điểm : Ưu điểm rõ ràng nhất của RMSprop là giải quyết và xử lý được vấn đề tốc độ học giảm dần của Adagrad ( vấn đề tốc độ học giảm dần theo thời kì sẽ làm việc training chậm dần, có thể dẫn tới bị tạm dừng hoạt động )Nhược điểm : Thuật toán RMSprop có thể cho kết quả nghiệm chỉ là local minimum chứ không đạt được global minimum như Momentum. Vì vậy người ta sẽ phối hợp cả hai thuật toán Momentum với RMSprop cho ra 1 thuật toán tối ưu Adam. Tất cả chúng ta sẽ trình bày nó trong phần sau.
6. Adam
Như đã nói ở trên Adam là sự việc phối hợp của Momentum và RMSprop . Nếu giảng giải theo hiện tượng lạ vật lí thì Momentum giống như một quả cầu lao xuống dốc, còn Adam như một quả cầu rất nặng có ma sát, vì vậy nó dễ dàng vượt qua local minimum tới global minimum và khi tới global minimum nó không mất nhiều thời kì dao động qua lại quanh đích vì nó có ma sát nên dễ tạm ngừng hơn.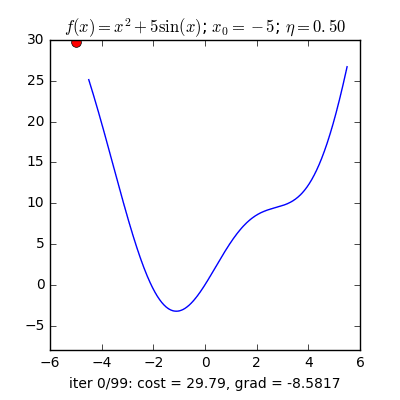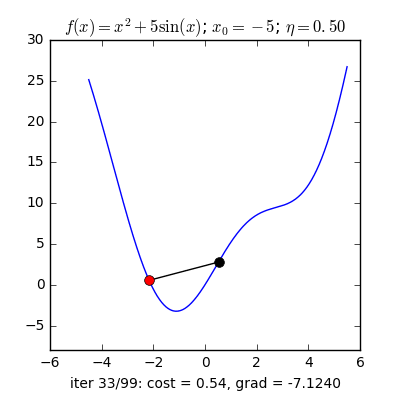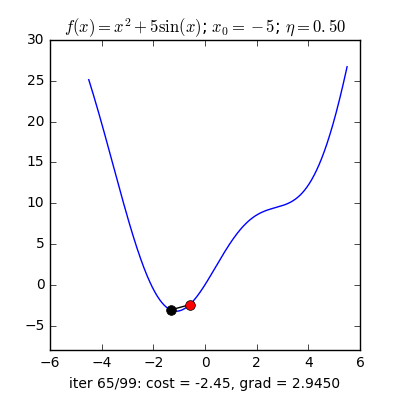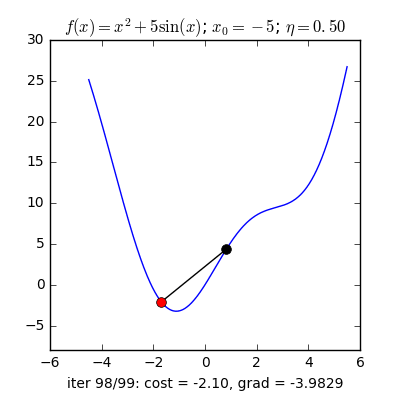 Công thức :
Công thức : 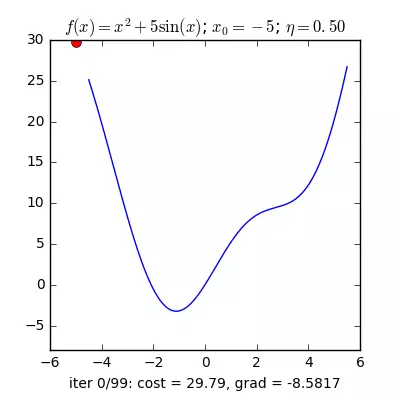 Vì sao lại sở hữu công thức đó ? Đó xem như một bài tập dành cho những bạn,……..thật ra thì mình nhát chưa tìm hiểu.
Vì sao lại sở hữu công thức đó ? Đó xem như một bài tập dành cho những bạn,……..thật ra thì mình nhát chưa tìm hiểu.
Tổng quan
Còn tồn tại rất nhiều thuật toán tối ưu như Nesterov (NAG), Adadelta, Nadam,… nhưng mình sẽ không còn trình bày trong bài này, tôi chỉ tập trung vào các optimizers hay được sử dụng. Hiện nay optimizers hay được sử dụng nhất là ‘Adam’. Qua hình trên ta thấy optimizer ‘Adam’ hoạt động tương đối tốt, tiến nhanh tới mức tối thiểu hơn các phương pháp khác. Qua nội dung bài viết này mình hy vọng các bạn cũng có thể hiểu và làm quen với optimizer trong các bài toán Machine learning, nhất là Deep learning. Còn nhiều biến thể của GD nhưng mình xin phép dừng nội dung bài viết tại đây. | Hy vọng nội dung bài viết có ích khi đối chiếu với bạn |

