
Chúng tôi vui mừng chia sẻ kiến thức về từ khóa Naive bayes la gi để tối ưu hóa nội dung trang web và tiếp thị trực tuyến. Bài viết cung cấp phương pháp tìm kiếm, phân tích từ khóa và chiến lược hiệu quả. Cảm ơn sự quan tâm và hãy tiếp tục theo dõi để cập nhật kiến thức mới.
Có thể bạn quan tâm
- Cacbon Là Gì? Tính Chất Vật Lý, Hóa Học & Ứng Dụng Của Cacbon
- Tiếp tuyến là gì? Định nghĩa, tính chất dấu hiệu nhận biết tiếp tuyến của đường tròn
- Tare Weight là gì? Ý nghĩa của Tare Weight trên container
- Khái niệm game lậu, game được cấp phép và cái nhìn công bằng từ game thủ
- Bảo tàng dân tộc học tiếng anh là gì? – https://leading10.vn
Chắc hẳn khi nhập môn Machine Learning mọi người cũng nghe qua về thuật toán phân lớp, hôm nay mình muốn giới thiệu cho mọi người một phương pháp đem lại hiệu quả tốt trong lớp các bài toán phân lớp hay dự đoán. Giải thuật mình muốn nói đến hôm nay là Naive Bayes – một trong những thuật toán rất tiêu biểu cho hướng phân loại dựa trên lý thuyết xác suất.
Bạn Đang Xem: Phân lớp với Navie Bayes Classification – Mô hình và ứng dụng
Lý thuyết về Bayes thì có nhẽ không còn quá xa lạ với tất cả chúng ta nữa rồi. Nó đây chính là sự liên hệ giữa các xác suất có xét tuyển. Điều đó gợi ý cho tất cả chúng ta rằng tất cả chúng ta có thể tính toán một xác suất không biết dựa vào các xác suất có xét tuyển khác. Thuật toán Naive Bayes cũng dựa trên việc tính toán các xác suất có xét tuyển đó.
Naive Bayes Classification (NBC) là một thuật toán phân loại dựa trên tính toán xác suất vận dụng định lý Bayes. Thuật toán này thuộc nhóm Supervised Learning (Học có giám sát).
Theo định lý Bayes, ta có công thức tính xác suất như sau:
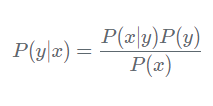 Do đó ta có:
Do đó ta có:
Trên thực tế thì ít khi tìm được tài liệu mà các thành phần là hoàn toàn độc lập với nhau. Tuy nhiên giả thiết này giúp phương pháp tính toán trở thành đơn giản, training data nhanh, đem lại hiệu quả bất thần với những lớp bài toán nhất định
Cách xác định các thành phần (class) của tài liệu dựa trên giả thiết này mang tên là Naive Bayes Classifier
Một trong các bài toán nổi tiếng hiệu quả khi sử dụng NBC là bài toán phân loại text
Trong bài toán này, mỗi văn bản được thể hiện thành dạng bag of words, hiểu nôm na là thể hiện xem có bao nhiêu từ xuất hiện và tần suất xuất hiện trong văn bản, nhưng bỏ qua trật tự các từ
Có 2 mô hình thuật toán Naive Bayes thường sử dụng là: mô hình Bernoulli và mô hình Multinomial. Trong bài toán này ta chỉ tìm hiểu mô hình Multinomial
Xem Thêm : Enctype = ‘Multipart / form-data’ nghĩa là gì?
Mô hình này chủ yếu được sử dụng trong phân loại văn bản mà feature vectors được tính bằng Bags of Words. Lúc này, mỗi văn bản được trình diễn bởi một vector có độ dài d đây chính là số từ trong từ vị. Giá trị của thành phần thứ i trong mỗi vector đây chính là số lần từ thứ i xuất hiện trong văn bản đó.
Ta tính xác suất từ xuất hiện trong văn bản P(xi∣y) như sau
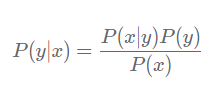 Trong số đó:
Trong số đó:
-
Ni là tổng số lần từ xi xuất hiện trong văn bản.
-
Nc là tổng số lần từ của tất cả những từ x1,…xn xuất hiện trong văn bản.
Công thức trên có hạn chế là lúc từ xi không xuất hiện lần nào trong văn bản, ta sẽ sở hữu Ni=0. Điều này làm cho P(xi∣y)=0
Để khắc phục vấn đề này, người ta sử dụng kỹ thuật gọi là Laplace Smoothing bằng phương pháp thêm vào đó vào cả tử và mẫu để giá trị luôn khác 0
 Trong số đó:
Trong số đó:
- α thường là số dương, bằng 1.
- dα được cộng vào mẫu để đảm bảo ∑i=1dP(xi∣y)=1
- Ta có bộ training data gồm E1, E2, E3. Cần phân loại E4
- Nhãn N là thư not spam, còn S là thư spam
- Bảng từ vựng: [w1,w2,w3,w4,w5,w6,w7].
- Số lần xuất hiện của từng từ trong từng email tương ứng với bảng
Giải bài toán bằng Python nhé
from sklearn.naive_bayes import MultinomialNB import numpy as np
Import thư viện cấp thiết
Xem Thêm : Những thông tin thú vị về Ancol Etylic – C2H5OH – VietChem
e1 = [1, 2, 1, 0, 1, 0, 0] e2 = [0, 2, 0, 0, 1, 1, 1] e3 = [1, 0, 1, 1, 0, 2, 0] train_data = np.array([e1, e2, e3]) label = np.array([‘N’, ‘N’, ‘S’])
Khai báo tài liệu training và nhãn
e4 = np.array([[1, 0, 0, 0, 0, 0, 1]])
Khai báo tài liệu tập test
clf1 = MultinomialNB(alpha=1) clf1.fit(train_data, label)
Dán nhãn tài liệu cho máy học
Rồi hiện giờ để máy predict tập test thôi
print(clf1.predict_proba(e4)) #Probabiliry of e4 for each class print(str(clf1.predict(e4)[0])) #Predicting class of e4
Kết quả
Như sk.learn trong python đã hỗ trợ tất cả chúng ta tính hết rồi từ tỉ lệ tới việc dự đoán tập test chỉ bằng vài dòng code đơn giản
Nội dung bài viết của mình đến đây là hết, hi vọng các chúng ta cũng có thể hiểu được qua về thuật toán Navie Bayes và vận dụng được nó, các chúng ta cũng có thể copy code để chạy nhiều trường hợp khác nhé.
Tài liệu tham khảo
- https://machinelearningcoban.com/2017/08/08/nbc/
- https://en.wikipedia.org/wiki/Naive_Bayes_classifier
- https://scikit-learn.org/stable/modules/naive_bayes.html

