
Chúng tôi rất vui mừng chia sẻ kiến thức sâu sắc về từ khóa Overfitting la gi và hi vọng rằng nó sẽ hữu ích cho các bạn đọc. Bài viết tập trung trình bày ý nghĩa, vai trò và ứng dụng của từ khóa trong việc tối ưu hóa nội dung trang web và chiến dịch tiếp thị trực tuyến. Chúng tôi cung cấp các phương pháp tìm kiếm, phân tích và chọn lọc từ khóa phù hợp, kèm theo các chiến lược và công cụ hữu ích. Hi vọng rằng thông tin chúng tôi chia sẻ sẽ giúp bạn xây dựng chiến lược thành công và thu hút lưu lượng người dùng. Cảm ơn sự quan tâm và hãy tiếp tục theo dõi blog của chúng tôi để cập nhật kiến thức mới nhất.

Khi xây dựng mỗi mô hình học máy, tất cả chúng ta cần phải lưu ý hai vấn đề: Overfitting (quá khớp) và Underfitting (chưa khớp). Đây đó chính là nguyên nhân chủ yếu khiến mô hình có độ xác thực thấp.
Bạn Đang Xem: Vấn đề Overfitting & Underfitting trong Machine Learning
Hãy cùng tìm hiểu những khái niệm cơ bản trong học máy và các vấn đề liên quan tới Overfitting và Underfitting.
Ước tính hàm mục tiêu trong Machine Learning
Học có giám sát (Supervised Learning) là phương thức học xác thực nhất trong học máy. Mô hình ước tính hàm mục tiêu (f) sẽ ánh xạ mỗi thành phần thuộc tập nguồn vào (X) sang một thành phần (xấp xỉ) tương ứng thuộc tập (Y)
Y = f(X)
Dựa theo những tính chất nguồn vào, ta có thể trình diễn được những nhãn đầu ra. Dự báo nhãn và thậm chí còn ta còn tồn tại thể xác định giá trị của nhãn thông qua Machine Learning.
Mô hình học máy được xây dựng qua bộ tài liệu huấn luyện. Kỳ vọng của mô hình là tổng quát hóa được đặc trưng (xấp xỉ) xác thực nhất với tổng thể. Điều này còn có ý nghĩa rất quan trọng. Vì tài liệu đầy vào của mỗi mô hình chỉ là một tập mẫu trong tổng thể, có thể không mang tính thay mặt đại diện cao và chứa nhiều nhiễu.
Tính phổ quát trong học máy
Trong học máy, hàm mục tiêu được xây dựng trên bộ tài liệu huấn luyện theo phương pháp đệ quy. Đây là phương pháp giúp tìm được tính phổ quát (tổng quát hóa) từ bộ tài liệu mẫu cụ thể. Vậy tính phổ quát là gì?
Phổ quát (tổng quát) là thước đo thẩm định và đánh giá một mô hình học máy được gọi là tốt hay là không. Nó thể hiện ở vấn đề một mô hình học máy có thể rút ra được những quy luật cho tổng thể từ bộ tài liệu mẫu không? Một mô hình có tính phổ quát, khi đó, mô hình sẽ vận dụng tốt với bất kì bộ tài liệu mới nào.
Tuy nhiên, trong quá trình học máy, ta cần lưu ý hai vấn đề. Đó là Overfitting và Underfitting. Đây là hai nguyên nhân chính trong việc khiến mô hình học máy có độ xác thực không tốt. Hay nói cách khác là không thể hiện được tính phổ quát của vấn đề.
Statistical Fit
Xem Thêm : Hạt ngọc dương vật là gì? Bệnh có nguy hiểm không?
Statistical Fit (độ xác thực trong thống kê) là chỉ độ gần đúng của hàm xây dưng với hàm hàm mục tiêu. Các phương thức được sử dụng trong thống kê khác với phương thức thực hiện trong học máy. Ví dụ, trong thống kê thường sử dụng các phương pháp ước tính để ước tính hàm mục tiêu. Tuy nhiên, trong học máy, ta lại không sử dụng phương pháp đó. Học máy dựa trên việc học từ tài liệu, ta đưa ra mô hình xấp xỉ xác thực nhất từ bộ tài liệu mẫu có thể có nhiễu.
Statistical Fit cũng được sử dụng trong học máy như một thước đo. Một số kỹ thuật trong thống kê cũng được vận dụng trong học máy (ví dụ: tính sai số).
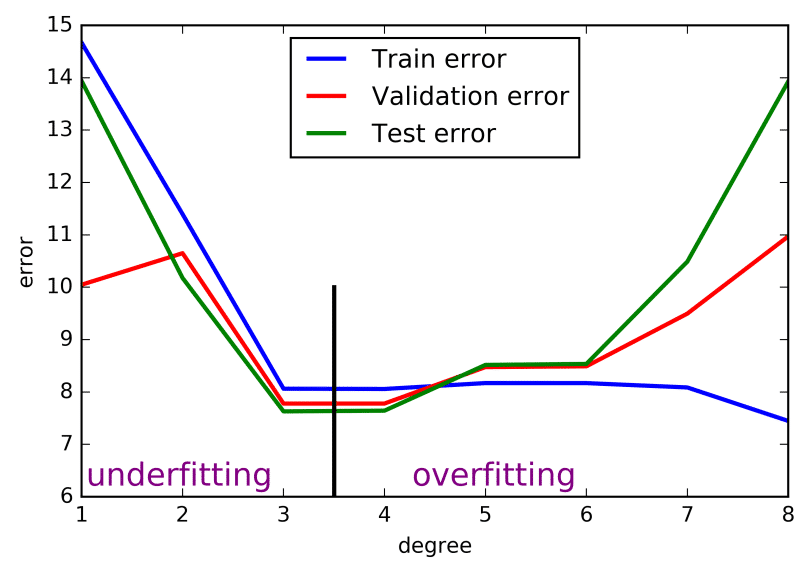
Overfitting trong học máy
Overfitting là hiện tượng kỳ lạ khi mô hình xây dựng thể hiện được cụ thể bộ tài liệu huấn luyện. Điều này còn có tức là cả tài liệu nhiễu, hoặc tài liệu thất thường trong tập huấn luyện đều được chọn và học để mang ra quy luật mô hình. Những quy luật này sẽ không còn có ý nghĩa nhiều khi vận dụng với bộ tài liệu mới có thể có dạng tài liệu nhiễu khác. Khi đó, nó ảnh hưởng tác động tiêu cực tới độ xác thực của mô hình nói chung.
Hiện tượng lạ Overfitting thường xẩy ra trong các mô hình phi thông số hoặc phi tuyến, những mô hình có sự linh hoạt cao trong xây dựng hàm mục tiêu.
Như vậy, rất nhiều thuật toán học máy phi thông số sẽ gồm có những thông số và kĩ thuật để ngăn cản và giới hạn múc độ học cụ thể của mô hình.
Ví dụ, bài toán cây quyết định là một thuật toán học máy phi thông số. Đây là thuật toán thường xẩy ra hiện tượng kỳ lạ Overfitting. Ta có thể tránh hiện tượng kỳ lạ này bằng phương pháp cắt tỉa cây (pruning).
Underfitting trong học máy
Underfitting (chưa khớp) là hiện tượng kỳ lạ khi mô hình xây dựng chưa tồn tại độ xác thực cao trong tập tài liệu huấn luyện cũng như tổng quát hóa với tổng thể tài liệu. Khi hiện tượng kỳ lạ Underfitting xẩy ra, mô hình này sẽ không phải là tốt với bất kì bộ tài liệu nào trong vấn đề đang nhắc tới.
Hiện tượng lạ Underfitting thường ít xẩy ra trong bài toán hơn. Khi Underfitting xẩy ra, ta có thể khắc phục bằng phương pháp thay đổi thuật toán hoặc là bổ sung thêm tài liệu nguồn vào.
Good Fittiing trong học máy
Good Fitting (vừa khớp) là nằm trong lòng Underfitting và Overfitting. Mô hình cho ra kết quả hợp lý với cả tập tài liệu huấn luyện và các tập tài liệu mới. Đây là mô hình lý tưởng mang được tính tổng quát và khớp được với nhiều tài liệu mẫu và cả những tài liệu mới.
Good Fitting là mục tiêu của mỗi bài toán. Tuy nhiên, trên thực tế, vấn đề này rất khó thực hiện. Để tìm được điểm Good Fitting, ta phải theo dõi hiệu suất của thuật toán học máy theo thời kì khi thuật toán thực hiện việc học trên bộ tài liệu huấn luyện. Ta có thể mô tả và thể hiện các thông số mô hình, độ xác thực của mô hình trên cả hai tập tài liệu huấn luyện và huấn luyện.
Theo thời kì và theo quá trình học, sai số của mô hình trên bộ tài liệu huấn luyện sẽ giảm xuống. Tuy nhiên, nếu quá trình training quá lâu, độ xác thực của mô hình có thể giảm do vấn đề Overfitting, và việc học sẽ thực hiện trên cả tài liệu nhiễu và tài liệu thất thường của cục huấn luyện. Song song, sai số với bộ tài liệu kiểm định sẽ tăng lên do khả năng phổ quát hóa của mô hình giảm xuống.
Xem Thêm : Fsc.edu.vn
Tất cả chúng ta kì vọng rằng tại thời khắc trước lúc sai số trên bộ tài liệu có tín hiệu tăng lên, khi đó, mô hình là tốt nhất trên cả bộ tài liệu huấn luyện và bộ tài liệu kiểm định.
Chúng ta có thể thực hiện ví dụ với bất kì thuật toán nào. Đây không phải là kỹ thuật hữu ích trong thực tế, bởi vì việc lựa chọn điểm dừng trong quá trình huấn luyện cần phải ghi nhận những giá trị trên bộ mẫu kiểm định, điều đó có tức là, bộ tài liệu kiểm định không còn được xem như là “unseen” hay độc lập khách quan với bộ tài liệu huấn luyện nữa. Bất kì sự hiểu biết nào về bộ tài liệu that data has leaked into the training procedure.
Trên đây có hai kỹ thuật mà chúng ta cũng có thể sử dụng để tìm ra điểm dừng tốt nhất trong quá trình huấn luyện, đó là kỹ thuật lấy lại mẫu (resampling methods) và kỹ thuật validation.
Làm thế nào để tránh Overfitting?
Cả hai hiện tượng kỳ lạ Overfitting và Underfitting đều khiến mô hình xây dựng có độ xác thực kém. Nhưng hiện nay, vấn đề phổ quát nhất xuất hiện là Overfitting.
Overfitting thực sự là một vấn đề quan trọng bởi vì việc thẩm định và đánh giá mô hình học máy trên bộ tài liệu huấn luyện sẽ khác biệt với việc thẩm định và đánh giá độ xác thực của tổng thể ( những tài liệu mà mô hình chưa gặp bao giờ).
Có hai kỹ thuật quan trọng trong việc thẩm định và đánh giá mô hình học máy và tránh hiện tượng kỳ lạ overfitting:
- Sử dụng kỹ thuật lấy lại mẫu để ước tính độ xác thực của mô hình
- Sử dụng tập Validation test
Lấy lại mẫu (resampling methods) là kỹ thuật phổ quát hơn. Khi đó, ta sẽ chia tập tài liệu thành k tập con. Cách này được gọi là k-fold cross validation. Điều này được cho phép bạn thực hiện huấn luyện trên các tập tài liệu khác nhau k lần, và từ đó, xây dựng ước tính độ xác thực của mô hình học máy với tài liệu mới.
Sử dụng Cross-validation là một tiêu chuẩn tốt trong học máy để ước tính độ xác thực của mô hình với bộ tài liệu mới. Còn trường hợp bạn có nhiều tài liệu, việc sử dụng tập Validation sẽ là một phương pháp tuyệt vời.
Tóm tắt
Bài này giới thiệu mô tả cho bạn rằng các vấn đề trong học máy được giải quyết và xử lý bằng các phương pháp thống kê.
Bạn được học rằng tổng quát hóa mô hình là tìm ra các quy luật của cục tài liệu và vận dụng với bộ tài liệu mới đạt được độ xác thực cao. Cuối cùng, bạn được tìm hiểu về những thuật ngữ trong xây dựng mô hình học máy.
- Overfitting: khi mô hình có độ xác thực cao với bộ tài liệu huấn luyện, nhưng độ xác thực thấp với bộ tài liệu mới (hay tài liệu tổng thể).
- Underfitting: khi mô hình có độ xác thực thấp trên cả bộ tài liệu huấn luyện và bộ tài liệu mô tả tổng thể mới.
Nguồn: https://machinelearningmastery.com

